论文摘趣 (1) -- CVPR专题
论文摘趣的第一期,我们来关注一下计算机视觉的“春晚” – CVPR。今年的CVPR在夏威夷召开,无论是从录取论文数还是到会人数来看都是空前的盛大。作为我第一次参加的学术会议,这次的CVPR之旅注定是我难忘的回忆。对于会议盛况的介绍网络上也能找到很多相关的文章了,我们还是回到论文上吧。平心而论,可能是由于论文录取数增加的原因,部分录取论文的水平实在是比较一般。当然,在逛海报的时候,我还是发现了不少有趣的闪光点的,也是今天论文摘趣专题要跟大家分享的。通过poster展示的方式让作者和读者进行直接的沟通,相互交流论文中的思路和细节,这是我觉得学术会议最有意思的地方。
一、享趣篇
1. Deep Multimodal Representation Learning From Temporal Data (link)
哈哈,略有私心,首先介绍的是我们这次录用为poster的论文 – 《从时序数据的多模态表示学习》。这是我硕士期间在PARC实习的工作成果之一。其实从现在的角度看,这篇文章的质量也是一般般。由于当初时间比较赶,论文里面很多实验和可视化分析其实是可以做得更好一些的。不过没想到的是,与会的很多人都对我的poster有着不少的兴趣。过来围观提问的老师、学生及公司的研究员络绎不绝。我觉得吧,作为至今为止少有的对 时序数据进行多模特表示学习 的工作,这篇论文还是有点意义的~
首先,多模态学习(Multimodal Learning)顾名思义是对于多模态数据(如图像、文本、视频、音频等)进行统一学习的任务。而多模态表示学习 (Multimodal representation learning)则是更关注于学习一个统一的数据表示(joint representation),这个统一的数据表示既融合了各个模态的信息,且与各模态的低层数据特性无关,是一个更抽象的统一概念。打个比方,“大笑”作为一个单一的概念,对于图像这个模态而言可以表现为“张开嘴的笑脸”,对于音频则是“笑声”,对于文本则是“大笑”这个词本身。多模态表示学习就是希望从不同模态的表示中学到一个类似“大笑”那样统一概念。然而,多模态表示学习通常并不是一件简单的事情。因为各个模态的低层表示(low-level representation)具有各自迥异的统计特性,以及相互之间非常复杂的非线性关系。近年来,由于深度学习的发展,人们开始用深度网络来先对各个模态提取较为高层的抽象表示(high-level representation),然后再进行多模态融合(multimodal fusion)来实现多模态表示学习。我们的工作的重点在于提出了一个专门针对多模态时序数据的多模态表示学习模型,这是前人工作中没有做到的。先放一张我们的海报,大家可以对照着看:
个人觉得这个工作最有意思的点在于:我们的模型受启发于多模态时序数据的本质特性(intrinsic characteristic),并且用简单的方法对这些特性进行建模。或许我们当中用到的一些方法不是十分的创新,但我们的模型中传达了对数据特性本身的深入理解和分析,并且在实际数据的实验中得到检验是有用的。下面我们来简单介绍一下各个模块设计的思路,具体的方法和公式可以阅读我们的论文。
-
多模态时序模块(Multimodal GRU Module)
时序数据最显著的特性当然就是它的时序结构。多模态时序模块的目的就是同时地进行 统一表示 以及 时序结构 的学习。这里我们用了一种基于循环神经网络(Gated Recurrent Network)的编码-解码框架(Encoder-Decoder),并对当中的神经单元进行适用于多模态的扩展。简单来说,每个单元中会涉及到三部分信息,分别对应两个模态各自的函数变换以及用于得到统一表示的函数变化。由于这里会涉及到一些繁琐的计算公式,感兴趣的朋友可以看论文里具体的描述。
-
互相关模块(Correlation Module)
这个模块启发与我们对多模态时序数据特性的发现:在很多的应用场景中,多模态时序数据之间的差异,往往是由于 使用不同的设备记录同样的事情 导致的。比如同样记录一个人在跑步,视频、音频和运动传感器都会得到不同模态的数据,但实际上这些数据都是记录着同样的事情。这个发现意味着:多模态时序数据之间具有很强的相关性!这对于很多非时序的多模态数据是不适用的。比如说对于图像和文本,它们之间的相关性来源于他们高层次语义层面的相关,跟多模态时序数据间的相关性是截然不同的。因此,我们在模型中加入了互相关模块,希望通过显式地增加各模块函数变换的相关性,从而得到更好的统一表示。这种最大化变换相关性的思路在以往 Canonical Correlation Analysis (CCA) 和 Correlational Neural Network 中也有用到。
-
动态加权模块(Dynamic weighting Module)
对于时序数据而言,一个常见的难题是数据的噪声水平(noise level)会随着时间的发展而动态地改变。对此我们加入了动态加权模块,隐性地对各个模态的噪声水平进行评估,然后得到各个模态的置信度权重,并根据这个权重进行加权地多模态融合。这里用到的方法借鉴了近几年十分热门的关注度模型(attention model),利用一个双边线性函数(bilienar function)得到各个模态的“关注程度”。
将这些模块整合到一起,便得到了我们最终的模型 – 互相关循环神经网络(Correlational Recurrent Neural Network)。这是一个通用的多模态时序数据表示学习框架,可以应用于不同的模态,不同的数据集,不同的任务当中。在我们论文的实验里,我们尝试了 视频-运动传感器 和 视频-音频 这两种不同的多模态数据组合,并应用到了动作识别、语音识别等不同的任务当中。在 视频-运动传感器 的实验当中,我们展示了不同损失函数对模型效果的贡献。尤其是对于跨模态预测的任务(cross modality learning 和 share representation learning, 详见论文),加入了跨模态重构以及互相关模块使模型的性能得到大幅度的提升。在 视频-音频 的实验当中,我们证实了我们的模型优于其他的基于深度学习的多模态表示学习方法。更有趣的是,我们的模型对于噪声具有更好的鲁棒性,这一点在海报最后一个表格中可以看出。
二、淘趣篇
无监督学习
1. Learning Features by Watching Objects Move (link)
通过捕捉运动的方式自动得到图像中的物体,并以此进行图像特征的无监督学习
对于关注特征学习的我来说,这篇来自于Facebook和伯克利的论文是十分有趣,想法简洁而又让人信服。而且Deepak小哥在poster前的讲解也是尽心尽力,我想我以后会更多关注他们组的一些工作了。首先这篇文章有一个关键而且颇为合理的假设:我们可以通过运动来发现这个物体(或者说分辨出物体与背景的区别)。举个例子:下图中有一只猫(左上),如果它静止不动的话,一个没见过猫的人可能会根据颜色等因素将这个物体分割成不同的部分(如右上)。但若这只猫动了(如左下),我们就可以通过整个物体的运动发现这些部分应该是属于“猫”这一个统一的物体的(如右下)。

发现猫这个物体之后,我们人类就会修改自己对“猫”的认识。当下次我们再见到这样的猫的时候,我们自然就会直接识别出猫这个整体了。同时这也说明了我们对这类图像有了更好的理解,即更好的“特征表示”。受到这个思路的启发,这篇论文就是希望:先通过捕捉运动的方式自动地得到图像中的物体,然后训练模型让它能够直接从图像输入中分割出物体来,从而学习到对这个图像更好的特征表示。为了得到物体的运动,论文对视频数据提取光流,然后将与背景运动不同的部分视为物体。分割出物体后的掩码图(mask)会作为训练的监督信号,让模型能够做到给定单一图像作为输入,输出图中物体的掩码图(类似图像分割)。通过这样不断的自动寻找物体并训练模型,我们就可以得到一个更好的图像特征表示了。
2. Self-Supervised Video Representation Learning With Odd-One-Out Networks (link)
通过解决“寻找多个片段中的乱序片段”这个辅助任务,进行视频的自监督学习
这篇文章是对视频进行自监督的表示学习,思路也颇有意思。论文首先设计了一个可以自监督完成的辅助任务:从几个视频片段中识别“奇怪”的片段。由于时序顺序对于视频来说是一个十分重要的特性,我们很自然地就会想到可以把“奇怪”片段定义为乱序的片段。因此,这个辅助任务就是一个让模型从几个片段中找到乱序片段的分类问题。通过学习解决这个辅助任务,模型可以学到视频中时序信息的模式,从而实现自监督的表示学习。

不得不提的是,之前已经有类似的工作,让模型鉴别视频片段是否乱序从而实现自监督的表示学习(order verification)。当我问及作者两者的比较之时,作者的回答是本文可以看作是之前工作的扩展版,即从二分类问题扩展为多分类问题。而且他们在实验中发现,一定程度的候选片段的增加(其中有一个乱序)会使模型效果变好。另外很关键的一点,文中使用的帧差堆叠(stack of difference of frames)的视频片段描述方式对模型性能的提升有巨大的帮助(将近10个点的提升)!
3. Unsupervised Learning of Depth and Ego-Motion From Video (link)
利用理论模型,将其中变量解耦合和重组,从而获得监督信号
这篇文章来自UC Berkeley和Google,作者Tinghui在讲解时的淡定和自信给我留下了很深的印象。文章希望从视频中无监督地学出深度和自运动信息,其思路是将视角合成(view synthesis)的结果作为模型的监督信号。大概做法是用两个网络分别生成深度信息和自运动信息,然后用视角合成模型对原图进行映射,然后将映射的结果与实际结果对比训练网络。
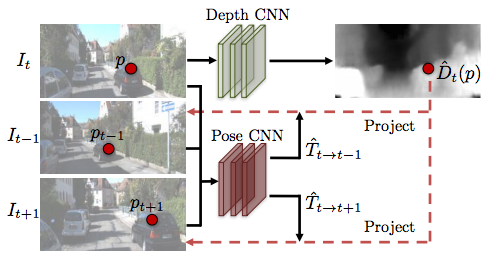
我觉得这个思路其实跟下文的 Neural Face Editing 有点类似,都是利用理论模型,将其中变量解耦合和重组,从而获得监督信号。对比一下就可以看到,这篇文章中用的是视角合成模型,Neural Face Editing 用的是人脸合成模型。视角合成模型中解耦合的变量是深度和运动参数,人脸合成模型解耦合的变量则是平面角度,反射度,光照度等。这种类似的思路其实跟我们最近在做的工作也非常相似,让我很受启发。
4. Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction (link)
通过不同通道之间的跨通道预测,实现数据的无监督学习
这篇来自UC Berkeley的文章其实是一篇我略有质疑的文章(欢迎有不同意见的朋友告诉我你们的想法)。文章思路很简单:通过不同通道(channel,也可以看作特征的不同维度)之间的跨通道预测,实现数据的无监督学习。比如将图像分为颜色通道和亮度通道,然后进行相互的预测。文中展示了这种学习方法对比与传统自编码器的优越性。
然而我觉得值得质疑的是,这种跨通道的预测方法应该是建立在不同通道间有一定相关性的前提之下的。当通道间(或者说特征各个维度间)是正交的时候,跨通道的预测感觉不太合理。当时我对作者提出了这个疑问,不过他只是默认我的说法而没有作出解释。同时他也说了在实验中,L和ab的分解方式比RGB的分解方式得到的结果要好(RGB也有一定用处)。或许其中还有一些东西是值得我们思考和探索的。
视频动作定位
1. CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos (link)
空间卷积降维,时间反卷积升维,从而得到更精细的动作边界(帧级别)
这应该是视频动作定位(Action Localization)最新 state-of-the-art 的代表之作了吧。我前段时间才开始关注动作定位这个问题,刚好在开会之前看到一篇知乎上原作者对自己文章的介绍,就不在这班门弄斧了。简单总结一下就是:空间卷积降维,时间反卷积升维,从而得到更精细的动作边界(帧级别)。之后还用了高斯密度估计的方法对预测分数进行后处理。总的来说是惊喜不多,但确实好用。
2. Temporal Action Localization by Structured Maximal Sums (link)
动态规划定位最佳起始位置和终点
同样是动作定位,这篇文章的做法就有点“另辟蹊径”的感觉了。首先,它把各个动作类别再细分为三类:动作开始,中间和结束。这样模型的输出便成为 \(C \times 3\) 个类别,其中 \(C\) 是动作类别的个数。然后再用动态规划的方法,求解一个结构和最大化的问题。具体怎么构建和求解这个问题可以参见论文中的介绍。

其它
1. Making Deep Neural Networks Robust to Label Noise: A Loss Correction Approach (link)
从含噪数据中估计标签转移矩阵,以纠正原本受标签噪声影响的模型
这篇文章是当天早上的第一个oral presentation,也是我觉得最有趣的一个(之后有两个都是best paper的presentation……)。文章要解决的是数据标签中含有噪声的问题,即部分数据的标签由于噪声的影响变成错误的标签。用数学语言来表达就是,对于一个数据集,我们可以将数据及其标签的联合分布表示为 \(p(x, \tilde{y}) = \sum_y p(\tilde{y} | y)p(y x)p(x) \),其中 \(y\) 是数据原本正确的标签,\(\tilde{y}\) 是受到噪声影响后的标签,\(p(\tilde{y} | y)\) 则表示了标签 \(y\) 转变成 \(\tilde{y}\) 的概率。另外我们可以得到一个关于标签的转移矩阵 \(T\),其中 \(T_{ij} = p(\tilde{y}=e^j | y=e^i)\)。如果这个转移矩阵 \(T\) 是已知,我们就可以通过前向纠正或者后向纠正的方法对预测的标签进行纠正。具体做法可以看论文里的介绍,感觉挺直观的,也不是我们这里要关注的重点。

算法的重点在于,如何从含有噪声的数据集中有效地估计出转移矩阵 \(T\)。文中的定理三说明了只要有足够的数据量和足够好的分类器 \(h\),我们就只需要从含噪数据中进行估计便可得到准确的 \(T\)。这个结论略微有点反常理,让人印象深刻。那么怎么估计矩阵 \(T\)呢,上图给出了算法的流程。首先,我们用已有的数据(含标签噪声)训练分类模型 \(h\)。然后,我们任意取出一部分数据集合 \(X’\)。对于每个标签类别 \(i\),我们选取 \(X’\) 中对该标签预测概率最高的那个数据 \(x^i\),即 \(x^i = argmax_{x\in X’} p(\tilde{y} = e^i | x)\)。那么 \(T_{ij}\) 的值可以由该分类模型对于这个数据 \(x^i\) 误分为其他类别 \(e^j\) 的概率值 得到,即 \(T_{ij}= p(\tilde{y} = e^j | x^i)\) 。得到估计的 \(T\) 后,我们就可以按前文所说的前向或后向纠正的方法重新训练模型 \(h\) 了。
2. Additive Component Analysis (link)
一个新的非线性降维方法
这篇文章来自CMU的Fernando组,内容是一个新的非线性降维方法,可以看作是主成分分析(PCA)的扩展。这个工作的思路很好理解。传统的PCA将高维数据映射到低维的子空间中,让高维数据可以由低维数据的线性组合近似。然而PCA的方法受限与其线性组合的限制,对高维数据的表达能力不足,因此人们想设计一种基于非线性组合的降维方法。从下图可以清楚的看到,与PCA相比,ACA的子空间的组合并不需要是线性的,这样可以增加低维空间的灵活程度和表达能力。
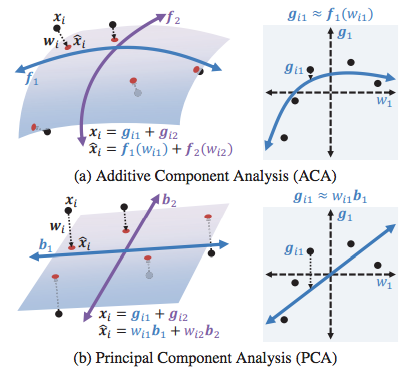
具体的实现涉及到如何共同学习基函数和各个成分,感兴趣的可以去看看论文(我是没细看了)。这里想再多讨论一下这个方法的特点。根据本人在poster session上听到的,ACA的优点有以下三点:1、非线性;2、可以从低维数据反向映射回高维数据;3、高效(不需要像PCA那样计算每个数据对的相似性)。然而一个很自然的问题是(当场也有人问了):这个方法跟自编码器(autoencoder)相比有什么优势呢?为什么我们不直接用简单的自编码器呢?很显然,ACA所提到的三个优点,自编码器都是具备的。当时听到作者是这么回答的:自编码器这类基于神经网络的方法始终是比较“黑盒子”的,其中的编码过程和正则化选择都不足够透明,需要很多工程性的投入以及会有过拟合和缺乏解释性的问题。而ACA则是类似PCA那样有比较清楚的数学解释。这个回答我还是可以接受的,你觉得呢?
三、后记
CVPR录取的论文毕竟太多,还有一些也颇有意思的论文没办法都一一介绍了。以下列出一些个人觉得让人有点启发的paper,感兴趣的可以去看看。
-
Deep Unsupervised Similarity Learning Using Partially Ordered Sets (link)
亮点:无监督怎么做到相似性学习?
-
Predictive-Corrective Networks for Action Detection (link)
亮点:收卡尔曼滤波启发提出的模型,故事说得蛮有意思的,但感觉有点后劲不足?
-
Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space (link)
亮点:结合类似deep dream的思路,通过输出层梯度的反向传播引导图像的生成。Jason在摊位介绍了好久,虽然每太完全懂,但还是推荐一下。特别有趣的是,其中的“分类器”网络貌似可以任意替换成其他网络从而得到其他数据集上的图像,即所谓的plug & play。
-
Network Dissection: Quantifying Interpretability of Deep Visual Representations (link)
亮点:印象最深的一点是,Bolei Zhou在poster展示的时候说他们的实验说明“grandmother neurons”现象是存在的,这个论点跟之前深度学习中关于分布式表示(distributed representation)的观点是相悖的。
-
Top-Down Visual Saliency Guided by Captions (link)
亮点:友情推荐同组实习生的论文。利用image captioning来top-down地定位visual saliency。个人觉得是 explainable AI 方向不错的思路。
-
Object Region Mining With Adversarial Erasing: A Simple Classification to Semantic Segmentation Approach (link)
亮点:挺有趣的oral paper。通过不断消除容易识别的区域,逐渐找到整个物体区域。
-
Order-Preserving Wasserstein Distance for Sequence Matching (link)
亮点:将序列匹配问题看作最佳搬运问题(距离度量则变成Wasserstein距离),再加上时序限制的正则化。好处是序列局部可以不必严格保序,而且据说速度比较快。
-
Neural Face Editing With Intrinsic Image Disentangling (link)
亮点:核心思想上文已经提到了。这篇文章loss很多,其中还用到了现成算法的输出作为外部guidance,感觉没有那么美观。
-
Improving Pairwise Ranking for Multi-Label Image Classification (link)
亮点:友情推荐一个很厉害的学长的论文。文章提出了一种改进的ranking loss目标函数,并且设计可以自动的进行阈值化或者选top k的操作,以此解决multi-label的分类问题。